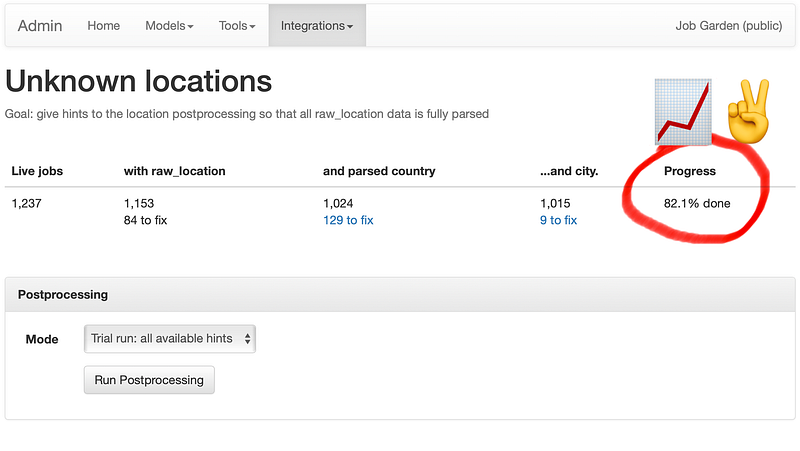
Behind the scenes, my admin system for tracking progress in parsing location data
Remember last week when I was talking about how to automatically turn 1,000+ descriptions of job locations into proper, structured, searchable data? At the time I was 38% done.
That is, 38% of the descriptions that just read “New York”, or “London, UK”, or “Redwood City, CA” (that’s California, not Canada) were turned into structured data understandable by the machine.
Today that number is… 82%! That’s decent enough progress for a week I think.
The way I’ve approached this location parsing system is different to the ways I’ve built similar systems in the past.
My two previous approaches would have been:
- Fallthrough: the system would look for the most common way that job postings describe location, which is “[city name], [country name]”. If that didn’t work, it would try the next most common: perhaps just the city name, or a city plus a state. Then after exhausting these patterns, it would fall through to a big list of special cases. To avoid incorrectly applying a pattern, these patterns would be very strict, and so there would be a lot of them and a manual moderation process too.
- Pay: the system would rely on a commercial third-party geocoding service such as the Google Maps API, which can take unstructured queries and return an address. Although simple on the surface, it has some downsides: it’s less likely to be effective because I know a lot more about these jobs than just a location string. Companies tend to have a limited number of countries of operating, for example, and that list of countries changes slowly. That data could hugely increase accuracy, but there’s no way to pass it in.
So I tried both approaches, and I wasn’t happy with either.
The fallthrough approach has most legs, but where it fails is that it can’t learn. You see, companies tend to be fairly consistent about how they describe job locations, and so the smartest way to decode a location for a new job is to first apply the patterns that worked for previous jobs from that company, not the patterns that are most common overall..
The approach I took instead is hinted, and it works not as a fallthrough but simultaneously and all at once.
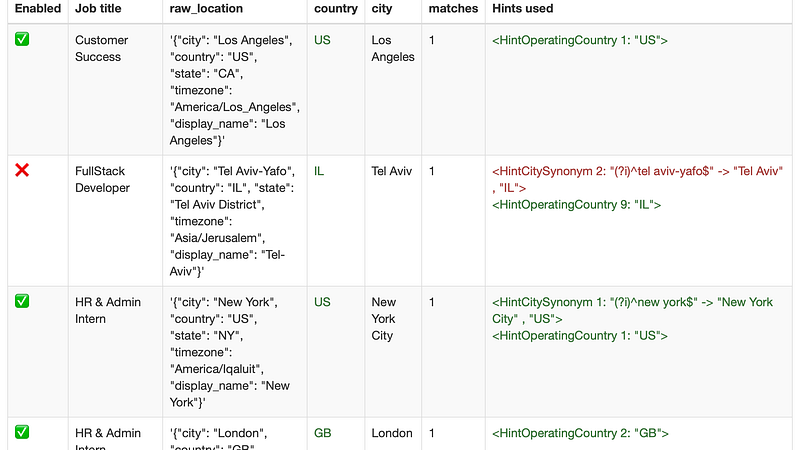
The hinted location parsing system in action
Here’s the hinting location parsing system in action.
How it works is that the system knows about a whole bunch of hints, like:
- potential operating countries
- ways of breaking up strings into cities and countries
- synonyms for city names
- etc.
Then I have a learning phase and an unattended phase.
During the learning phase, the system applies every single hint in all combinations and permutations. So instead of just trying to figure out one way to interpret the location description, it tries a dozen different routes, all at once. Then it presents to me the one or two routes which produce sensible-looking results, and what hints it used along the way.
The learning phase is interactive, so at that point I accept some hints and decline others.
In the screenshot about you can see this system in action. In green are hints that I’ve said are okay to use for jobs from this company in the future. In red is a hint that the system says produces a good result, so it recommends it, but I haven’t accepted it yet.
So I run through and accept hints.
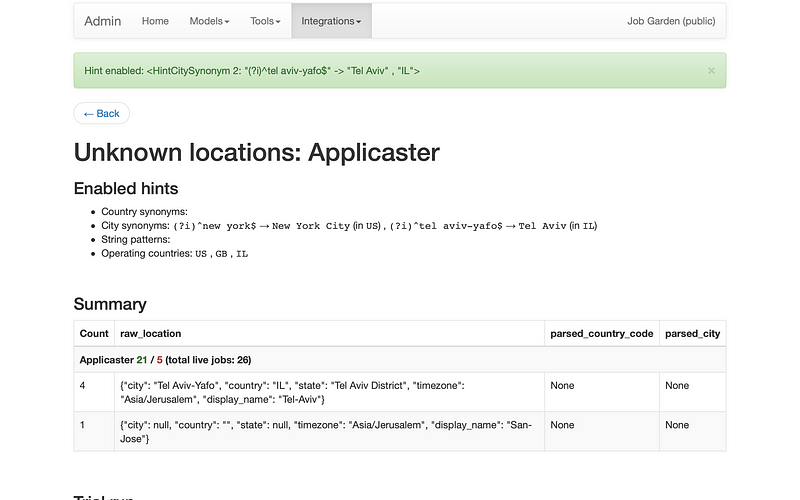
I also look at screens like this. This one shows me what hints are enabled, and what location descriptions are as-yet unparsed.
Then, in the unattended phase, the system runs only with the hints I’ve approved, and it runs as part of the usual automatic job syncing process. It runs in this strict mode so I can be confident it’s not going to give any batshit-incorrect results behind my back.
When I started coding (my first commercial programming gig was 20 years ago) I never would have done this. I would have looked for a clever and spare solution. Trying all possible routes at once just to see what happens? Computers are so fast now!
Such abundance!
We have clock cycles to burn!
Another point about this route:
Getting structured location data from job postings is now two distinct tasks:
- feature extraction (getting text that resembles location descriptions out of web pages)
- feature categorisation (turning this text into known city names and country names)
The first is done by recognising regular structures, which I currently write pattern-matching code to do, and it’s slightly different for most websites.
The second task can be thought of as a sparse matrix where particular hints are ticked if useful for any given company. Passing the extracted features through the matrix results in the categorised features.
What’s neat is that these tasks are both really well understood machine learning tasks.
What’s also neat is that, to make machine learning work well, you need a bunch of preliminary structure and a ton of training data. Well I have the structure now (extraction patterns, hints, and companies) and I have the training data (a system which can mechanically produce correct structured data 82.1% of the time).
This is perfect grist to chuck into the machine learning mill so that, in the future, I won’t need to write any more company web page-specific code: the system can learn how to do it itself.
So by doing this work with 1,000 jobs, I’ll need to continue developing it by this current method to let’s say 20,000 jobs, but beyond that I can see a clear approach to scale to a million jobs with minimal marginal effort.
What’s insane is I never would have seen this particular mountain pass without getting stuck in. Get your hands dirty. The material will tell you what it wants to do.
Not that I’ve ever done anything with machine learning (I only know the characteristics of tasks that are tractable to it) but we’ll cross that bridge when we come to it.
When you see a location for a job on Job Garden, it now passes through the system above. It’s not being used for anything new — yet.
Next week: a bit of maintenance, and back to adding handy features I hope. Thank goodness.
Behind the scenes, my admin system for tracking progress in parsing location data
Remember last week when I was talking about how to automatically turn 1,000+ descriptions of job locations into proper, structured, searchable data? At the time I was 38% done.
That is, 38% of the descriptions that just read “New York”, or “London, UK”, or “Redwood City, CA” (that’s California, not Canada) were turned into structured data understandable by the machine.
Today that number is… 82%! That’s decent enough progress for a week I think.
The way I’ve approached this location parsing system is different to the ways I’ve built similar systems in the past.
My two previous approaches would have been:
So I tried both approaches, and I wasn’t happy with either.
The fallthrough approach has most legs, but where it fails is that it can’t learn. You see, companies tend to be fairly consistent about how they describe job locations, and so the smartest way to decode a location for a new job is to first apply the patterns that worked for previous jobs from that company, not the patterns that are most common overall..
The approach I took instead is hinted, and it works not as a fallthrough but simultaneously and all at once.
The hinted location parsing system in action
Here’s the hinting location parsing system in action.
How it works is that the system knows about a whole bunch of hints, like:
Then I have a learning phase and an unattended phase.
During the learning phase, the system applies every single hint in all combinations and permutations. So instead of just trying to figure out one way to interpret the location description, it tries a dozen different routes, all at once. Then it presents to me the one or two routes which produce sensible-looking results, and what hints it used along the way.
The learning phase is interactive, so at that point I accept some hints and decline others.
In the screenshot about you can see this system in action. In green are hints that I’ve said are okay to use for jobs from this company in the future. In red is a hint that the system says produces a good result, so it recommends it, but I haven’t accepted it yet.
So I run through and accept hints.
I also look at screens like this. This one shows me what hints are enabled, and what location descriptions are as-yet unparsed.
Then, in the unattended phase, the system runs only with the hints I’ve approved, and it runs as part of the usual automatic job syncing process. It runs in this strict mode so I can be confident it’s not going to give any batshit-incorrect results behind my back.
When I started coding (my first commercial programming gig was 20 years ago) I never would have done this. I would have looked for a clever and spare solution. Trying all possible routes at once just to see what happens? Computers are so fast now!
Such abundance!
We have clock cycles to burn!
Another point about this route:
Getting structured location data from job postings is now two distinct tasks:
The first is done by recognising regular structures, which I currently write pattern-matching code to do, and it’s slightly different for most websites.
The second task can be thought of as a sparse matrix where particular hints are ticked if useful for any given company. Passing the extracted features through the matrix results in the categorised features.
What’s neat is that these tasks are both really well understood machine learning tasks.
What’s also neat is that, to make machine learning work well, you need a bunch of preliminary structure and a ton of training data. Well I have the structure now (extraction patterns, hints, and companies) and I have the training data (a system which can mechanically produce correct structured data 82.1% of the time).
This is perfect grist to chuck into the machine learning mill so that, in the future, I won’t need to write any more company web page-specific code: the system can learn how to do it itself.
So by doing this work with 1,000 jobs, I’ll need to continue developing it by this current method to let’s say 20,000 jobs, but beyond that I can see a clear approach to scale to a million jobs with minimal marginal effort.
What’s insane is I never would have seen this particular mountain pass without getting stuck in. Get your hands dirty. The material will tell you what it wants to do.
Not that I’ve ever done anything with machine learning (I only know the characteristics of tasks that are tractable to it) but we’ll cross that bridge when we come to it.
When you see a location for a job on Job Garden, it now passes through the system above. It’s not being used for anything new — yet.
Next week: a bit of maintenance, and back to adding handy features I hope. Thank goodness.